Introduction
Data mesh is a fresh approach to using data to create organizational value. A data mesh aims to increase the availability and accessibility of data for business operations by directly connecting data producers, owners, and consumers. The data mesh strategy’s main objective is to improve business results of data-centric solutions while also pushing for the adoption of cutting-edge data architectures.
As a result, leading-edge practitioners have started to deploy data mesh on a larger scale. More importantly, a data mesh is not just a rigid reference architecture or a single tool. Rather, it’s an organizational and architectural model developed to address and mitigate the shortfalls of years of data challenges and failures.

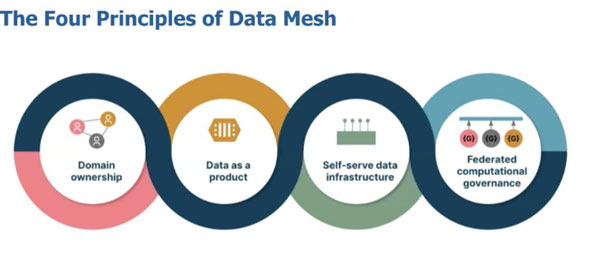
The four core principles of data meshing are
- Principle 1: It focuses on handing over end-to-end data ownership to the domain or business lines. Usually, the data management team doesn’t have a domain context. The data team is run parallelly to the main team and never aligned to the business operations, resulting in a constant context switch. To eliminate this, the data mesh concept considers giving end-to-end data in charge of the domain or business lines.
- Principle 2: Here, data is a product that can create monetization opportunities or develop services that can help firms reduce costs. However, companies measure value, and data is an asset you can package for consumption.
- Principle 3: Here, a self-serve data infrastructure is developed that can reduce the company’s choke points. The critical point here is that the platform must serve a broader user base for business or domain contexts instead of simply enabling self-serve data infrastructure for technical experts.
- Principle 4: It relates to a query we always get when we introduce data mesh to the audience: How to implement governance in a federated model?
Comparison between traditional data models to data mesh
| Traditional Data Models | Data Mesh |
| It supports centralized data teams that work for multiple domains. | It assists Autonomous Domain Teams. |
| Manages data, code, and policies as a single entity. | Manages pipelines and codes independently. |
| Designed for specialists | Designed for all types of users. |
| It is centralized and optimized for control. | It is centralized and optimized for scale. |
| Forceful domain awareness | It is domain agnostic. |
Oracle’s vision of the data mesh
Data mesh includes three new focus areas to run a data-driven architecture on the technical front.
- Tools that offer data products such as data analytics, data collections, and data events.
- It has distributed and decentralized data architectures that assist companies who select to transition from traditional monolithic architectures to hybrid-cloud and multi-cloud computing.
- Data in the movement for companies that can’t rely purely on centralized, static, and batch-oriented data. Instead, they move towards streaming-centric pipelines and event-driven data ledgers for real-time data events that offer timely analytics.
Data mesh challenges
The major challenges of a data mesh stream come from the complications inherent to handling multiple data products across multiple autonomous domains. Here are the main data mesh challenges,
- Multi-domain data duplication
- Federated data governance & quality assurance
- Change management
- Cost & risk
- Cross-domain analytics
Data mesh benefits
The key benefits of using the data mesh approach are
- Agility and scalability
- Cross-functional domain teams
- Faster data delivery
- Strong central governance and compliance
- Total clarity towards the data’s value
- Greater than 99.999% availability of operational data
- Ten times faster innovation cycles
- More than 70% drop in data engineering.
Technology trends are making data mesh a viable solution.
- 70-80 percent of digital transformations don’t give positive results.
- Expenses for operational data outages are on the rise.
- Cloud lock-in is happening & may end up becoming more expensive.
- Data lakes succeed very rarely and are only focused on analytics.
- The growth of distributed data is forcing a more efficient, effective, and economical architecture.
- Company silos worsen the data-sharing problems.
- Data is the glue for creating a competitive edge, and it is imperative to handle it well.
Data mesh use cases
Customer 360 view: It will support customer care in minimizing median handle time, boosting first contact resolution, and improving customer experience. You may also implement a single view of the customer via marketing to the next-best-offer decision or predictive churn modeling.
- Data privacy management: It will secure customer data by creating compliance with ever-emerging regional data privacy laws such as VCDPA (The Virginia Consumer Data Protection Act) before making it available to data users in the business domains.
Hyper segmentation: It enables marketing teams to deliver the right campaign to the right customers at the correct time and through the necessary channel.
- Federated data preparation: It enables domains to provide quality and trusted data for their data analytics workloads.
- IoT device monitoring: It offers product development teams insights into edge device usage patterns for continuous improvement of product adoption & profitability.
Implementing data mesh through a data product platform
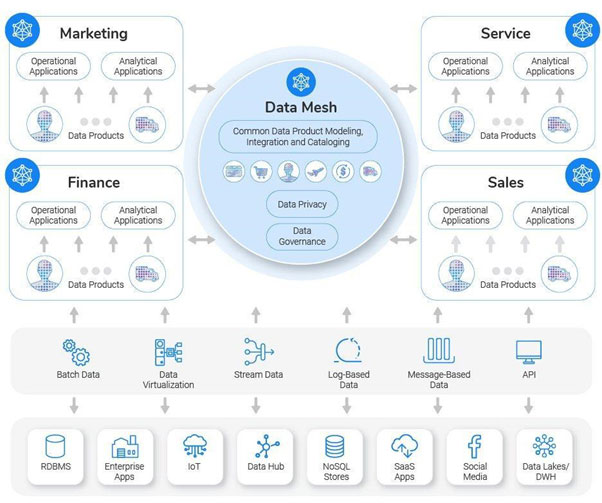
With the help of a decentralized design pattern, a real-time data product platform is the optimal deployment technology for a data mesh architecture. A data product platform develops and delivers data products of connected data from various sources to offer a real-time and holistic view of the business to analytical and operational workloads. A live data product platform generates a semantic definition of the various data products crucial to the business. It also sets up the data ingestion ways and the required central government policies to protect and secure the data in the data products as per imposed regulations.
Conclusion
Data mesh is not a short-term project. Instead, it’s an organizational mindset, an architectural evolution, and a different approach to data value at scale. But the changes to be incorporated through data mesh must be approached methodically and deployed over a period of time in a maturity model.
FAQs
1. Which functional capabilities will a data mesh support?
A: Adata mesh will support the following functional capabilities:
- Data catalog
- Data engineering
- Data governance
- Data preparation and orchestration
- Data persistence layer
- Data integration & delivery.
2. What are the three approaches to implementing a data mesh?
A: The three approaches to implementing a data mesh are
- Query-Driven Data Mesh
- Event-driven Data Mesh
- File-Based Data Mesh.
3. What is a data mesh pattern?
A: While allowing new levels of agility and data governance within the enterprise, it brings a “product thinking” approach to a task.
4. What are some big brand companies that have implemented or are on the verge of deploying a data mesh?
A: Some big brand companies that have implemented or are on the verge of deploying a data mesh are
- JPMorgan Chase
- HSBC
- Intuit
- Zalando
5. What are the attributes of a data mesh?
A: The attributes of a data mesh are,
- Decentralization
- Distributed security (Data encryption, Data Privacy Management, Data Masking, Identity Management, and GDPR & CCPA compliance)
- Data product mindset.
6. What is a data mesh score?
A: A data mesh score is purely dependent on how complex your processes are. It also applies to the number of systems or domains you have, the data team size, and the data governance priority. If you have a higher data mesh score, your current processes will benefit significantly from using a data mesh.
7. Which non-functional capabilities will a data mesh support?
A: Adata mesh will support the following non-functional capabilities.
- Data scale, performance & volume
- Distribution
- Accessibility
- Security.


