The topic of mental health is often brought up but rarely discussed openly in personal life conversations. The increasing use of technology has led professionals in the tech industry to work harder and improve their skills to keep up with the competitive environment. However, not everyone can adapt easily, which can negatively impact their mental well-being and how they handle situations. Employees may experience vulnerabilities such as peer pressure, anxiety attacks, and despair. In response to growing mental health issues and the need for better healthcare, researchers are exploring the use of machine learning applications.
This paper presents a comprehensive examination of machine learning methods in predicting mental health disorders. Additionally, the OSMI website conducts surveys to identify employees and working professionals who may be facing mental health challenges. By analyzing the survey data, a prediction model can be developed to help companies identify employees struggling with mental health issues and create a supportive and communicative work environment. The accuracy of different machine learning algorithms in identifying mental health issues was evaluated using various criteria, and the most accurate model achieved a prediction accuracy of 81.5 percent.
Furthermore, the paper discusses the methodology, analysis, and potential future developments of machine learning in the field of mental health.
Introduction:
Mental health encompasses a person’s emotional, psychological, and social well-being. Being mentally healthy does not imply the absence of negative emotions, but rather the ability to cope with daily challenges effectively. Mentally healthy individuals possess emotional regulation skills and can navigate difficulties resiliently. Awareness of one’s own feelings, both positive and negative, plays a crucial role in maintaining mental well-being. Recognizing when professional help is needed is a sign of mental fitness. To raise awareness about mental health, World Mental Health Day is observed annually.
Mental illness is a prevalent global issue, affecting approximately 300 million people worldwide. Prolonged periods of moderate or severe depression can lead to reduced functioning and impairment. Disturbingly, depression has been a leading cause of suicide, particularly among individuals aged 15 to 29 (WHO, 2018). Effective treatments for depression, such as therapy and antidepressants, exist. However, due to stigma and insufficient resources, many individuals do not receive the necessary support. Inadequate assessment further hinders proper treatment, with misdiagnosis and underdiagnosis being common (WHO, 2018).
In today’s rapidly growing IT industry, working professionals often experience high levels of stress. The constant pressure can lead to mental strain, resulting in a loss of interest in work and decreased productivity. Creating a positive work environment is crucial for the well-being of employees. Early recognition of symptoms is essential for preventing the progression of severe mental disorders such as schizophrenia, depression, bipolar disorder, and related conditions. It is imperative for every department within an organization to provide appropriate resources and facilities to promote the mental health of their employees.
In the future, technology can play a significant role in predicting and monitoring individuals’ mental health before it escalates. Leveraging individuals’ health check-up data can provide valuable insights for treatment and maintain a record of their well-being. Protecting and improving mental wellness through appropriate measures is of utmost importance.
Literature Review:
In general, mental health is a crucial aspect of overall well-being, and it is important for individuals to have mental health literacy to understand and support those who are struggling with mental health issues. Awareness and knowledge about mental health factors, symptoms, available resources, and treatment methods are essential for promoting positive attitudes and providing effective support to individuals with mental health disorders.
The whitepaper highlights the prevalence of various mental health disorders, such as depression, anxiety, PTSD, schizophrenia, and bipolar disorder, and emphasizes the importance of early recognition and intervention for better outcomes. It also discusses the need for a supportive working environment in the IT industry, as professionals in this field often face high levels of stress, which can negatively impact their mental well-being and productivity.
Furthermore, we explore the role of technology in the treatment of mental health issues. Various technologies, including machine learning, deep learning, computer vision, and cloud computing, are being employed to improve the conditions of mental health patients and enhance the effectiveness of diagnosis and treatment. The use of these technologies holds promise for providing personalized and efficient mental health care.
The research project presented in the paper utilizes machine learning models and ensemble classifiers to predict the mental health of working professionals in the IT industry. By analyzing the data collected from the OSMI survey, the project aims to understand the mental health conditions of individuals in this sector and provide insights to create a more supportive and empathetic work environment.
Overall, the whitepaper emphasizes the importance of mental health awareness, early intervention, and the integration of technology in addressing mental health issues. By promoting mental health literacy and implementing effective strategies, societies can work towards creating a safer and more inclusive environment for individuals with mental health disorders, ultimately improving their overall well-being and quality of life.
Background Study about Mental Health
Mental health issues can significantly impact an individual’s well-being and overall quality of life. It is crucial to understand that mental health disorders are not personal weaknesses or character flaws but rather medical conditions that require proper treatment and support. In the tech industry, where high levels of stress and demanding work environments are common, addressing mental health concerns becomes even more important.
- Anxiety disorders are characterized by excessive and persistent worry, fear, or apprehension. It can manifest as generalized anxiety disorder, panic disorder, social anxiety disorder, or specific phobias. These conditions can severely impact an individual’s ability to function and may lead to physical symptoms such as increased heart rate and difficulty concentrating.
- Bipolar disorder is characterized by extreme mood swings, including episodes of mania and depression. People with bipolar disorder experience intense highs (mania) and lows (depression), which can disrupt their daily lives and relationships. The symptoms and severity can vary from person to person.
- Depression is a common mental health disorder characterized by persistent feelings of sadness, loss of interest or pleasure, changes in appetite or weight, sleep disturbances, fatigue, and difficulty concentrating. It is not just feeling sad, but a pervasive and persistent feeling of hopelessness and despair that affects various aspects of life.
- Disassociation and disconnection disorder is a condition where individuals experience a disconnection from their thoughts, emotions, and sense of identity. They may feel detached from themselves or their surroundings, leading to a sense of unreality or dissociation.
- Eating disorders are characterized by abnormal eating habits that significantly impact physical and mental health. Common types of eating disorders include anorexia nervosa, bulimia nervosa, and binge eating disorders. These disorders often involve distorted body image, extreme weight loss or gain, and unhealthy relationships with food.
- Obsessive-compulsive disorder (OCD) is an anxiety disorder in which individuals experience intrusive thoughts (obsessions) and engage in repetitive behaviors or mental rituals (compulsions) to alleviate anxiety. OCD can significantly impair daily functioning and cause distress.
- Post-traumatic stress disorder (PTSD) can develop after experiencing or witnessing a traumatic event. Individuals with PTSD often experience intrusive memories, nightmares, flashbacks, and intense emotional distress related to the traumatic event. It can significantly impact their ability to function and may lead to avoidance of triggers associated with the trauma.
- Psychosis refers to a loss of contact with reality, characterized by hallucinations, delusions, and disorganized thinking. It can be caused by various factors, including underlying mental health conditions, substance abuse, or certain medical conditions.
- Schizophrenia is a complex psychotic disorder that affects a person’s thoughts, emotions, and perception of reality. It is characterized by symptoms such as hallucinations, delusions, disorganized speech and behavior, and impaired cognitive function. Individuals with schizophrenia often require long-term treatment and support.
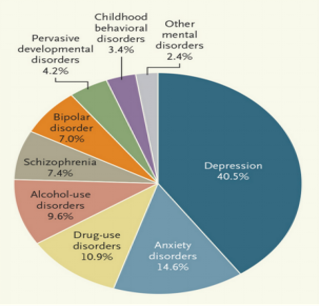
People with mental health disorders, including those mentioned above, are at a higher risk of suicide. It is crucial to provide appropriate care, support, and intervention to individuals struggling with these conditions to prevent tragic outcomes.
Addressing mental health issues in the tech industry requires a holistic approach involving employers, colleagues, mental health professionals, and society as a whole. It is essential for employers to prioritize and promote mental health in the workplace, providing resources such as counseling services, mental health benefits, and supportive policies. Colleagues can contribute by fostering a supportive and inclusive work environment where individuals feel comfortable discussing their mental health and seeking help when needed. Society should aim to reduce the stigma surrounding mental health and increase awareness and understanding of these conditions.
By conducting research and utilizing technology, such as machine learning, data analysis, and predictive modeling, it is possible to gain insights into the prevalence and impact of mental health issues in the tech industry
Indeed, mental illnesses can stem from a wide range of factors, often occurring in combination. Here are some factors that may influence the development of mental illnesses:
- Biological Imbalance: Brain chemistry and neurotransmitters play a significant role in mental illnesses. Imbalances or changes in these chemical messengers can be associated with various mental disorders.
- Genetic Factors: Research has shown that genetic predisposition can contribute to the development of mental illnesses. Having family members with mental disorders increases the likelihood of an individual developing similar conditions.
- Environmental Exposures: Certain environmental factors can increase the risk of developing mental illnesses, particularly during critical periods of development. For example, exposure to substances like drugs or alcohol during pregnancy can impact the baby’s mental health.
- Life Experiences: Traumatic events, such as physical or emotional abuse, neglect, loss of a loved one, or significant life changes, can have a profound impact on mental well-being. These experiences can contribute to the development of mental disorders such as depression, anxiety, or post-traumatic stress disorder.
Common symptoms of mental illness can vary depending on the specific disorder. However, there are some general symptoms that are often observed:
- Excessive Fear or Uneasiness: Persistent feelings of fear, worry, or uneasiness, often disproportionate to the situation. This can manifest as phobias, generalized anxiety, or panic attacks.
- Sleep or Appetite Changes: Disruptions in sleep patterns, such as insomnia or excessive sleepiness, as well as changes in appetite, lead to significant weight loss or gain.
- Problems with Thinking Difficulties in concentration, memory, decision-making, or problem-solving. Individuals may struggle to focus on tasks or retain information.
- Mood Changes: Unexplained and drastic shifts in mood, such as feeling intense sadness, hopelessness, irritability, or sudden bursts of euphoria These mood changes may not align with the person’s circumstances.
- Withdrawal symptoms include loss of interest or pleasure in activities once enjoyed, social withdrawal, isolation, and a general sense of apathy or detachment from the world.
It’s important to note that these symptoms can vary in severity and duration, and the presence of these symptoms alone does not necessarily indicate a mental illness. A comprehensive evaluation by a mental health professional is necessary for an accurate diagnosis.
Raising awareness about mental health and promoting understanding, early intervention, and access to appropriate treatment and support are essential for individuals living with mental illnesses.
Methodology
The proposed methodology involves utilizing the data from the OSMI health survey to develop a prediction model that can assess the mental health status of employees in the technology or IT industry. Here are the steps involved:
- Data Cleaning: The first step is to clean the OSMI survey data by removing any inconsistencies, missing values, or errors. This ensures that the dataset is reliable and ready for analysis.
- Exploratory Data Analysis: Conduct exploratory data analysis to gain insights into the dataset. Analyze the trends, patterns, and correlations among different variables in the survey. This analysis helps to understand the prevalence of mental health diseases and disorders within the technology-based industry.
- Feature Selection: Identify the relevant features or variables from the dataset that have the most significant impact on predicting mental health outcomes. This step helps to reduce dimensionality and focus on the key factors influencing mental health.
- Model Development: Utilize machine learning models to build a prediction model based on the selected features. Different algorithms, such as logistic regression, decision trees, random forests, or neural networks, can be used to train the model.
- Model Evaluation: Evaluate the performance of the prediction model using appropriate evaluation metrics. Split the dataset into training and testing sets to assess the model’s accuracy, precision, recall, and other relevant metrics.
- Integration and Deployment: Integrate the developed prediction model into various technologies and applications, such as employee monitoring systems, wellness apps, or HR software. This allows organizations to assess the mental well-being of their employees and create a supportive environment.
- Continuous Improvement: Continuously update and refine the prediction model as new data becomes available. This ensures that the model remains accurate and relevant over time, accommodating changing trends and patterns in mental health conditions.
The Open Sourcing Mental Illness (OSMI) survey data serves as the foundation for this methodology, providing valuable insights into the mental health landscape in the technology industry. By leveraging this data and developing a predictive model, organizations can better understand the mental health needs of their employees and create an environment that supports their well-being.
As The world becomes increasingly intensive and competitive, working professionals are getting mentally pressured to cope with the competitive environment. Sometimes this is not the only reason for their mental health deterioration. The companies are the stakeholders who can use our model to understand their employees and create a supportive environment for communicative and healthy working employees. Different organizations can use the model to predict how their employees are doing under certain circumstances and to build a strong, responsive environment for them to communicate and heal. The goal should be to create an environment where employees are not worried about expressing themselves and are coming forward to get treated for their mental well-being.
OSMI surveys are conducted every year (or so) in many companies across the world to get a better understanding of the condition of their employees. For now, it might be limited to working professionals, but it can be further extended to students, youngsters, and teenagers who are not less mentally stressed. Predicting how and why they have been going through what they are going through can be ultimately useful in helping them stabilize their condition.
To accomplish the dreams we’ve had for a long time, we need to first schedule the tasks and create the prediction model, which in turn can be added to various technologies and apps for better usage. For the prediction model, the OSMI data that we have gathered for different years has to be cleaned, and then we need to analyze the trends and correlations among the columns (that the survey has covered) to get a grip on the dataset. Then, using different Machine Learning models, we would do the prediction so that it could even predict newer data that would be added in the future and could be used in apps and software to reach out to as many people as we could.
OSMI, also known as Open Sourcing Mental Illness, has always been and is distinguished as an esteemed non-profit organization that focuses mainly on educating people, raising awareness, and handing out resources to support a good and greater cause, here stated as mental health or wellness in the IT/tech and open source (OSS) communities.
The main goal of the project is to gauge how mental health diseases and illnesses are viewed in the Technology or IT industry, varying from the different types of illnesses in all sorts of professions and positions. Also to understand the prevalence of certain mental health diseases and disorders within the technology-OSMI-based industry. The Open Sourcing Mental Illness or OSMI, health survey team, which consists of categorized volunteers who ultimately use the data derived from the thousands and lakhs of surveys filled by professionals in the IT industry, drives our work in raising awareness and improving conditions for those with mental health disorders in the IT workplace
Technology employed in current times to treat mental health illnesses
Table 1. Percentage of studies for different sorts of mental disorders
| Types of Mental Health Issues | Percentage of Studies |
| Mental illness | 5 |
| Schizophrenia | 8 |
| Anxiety | 17 |
| Depression | 30 |
| Suicidal ideation | 10 |
| Personal problem | 15 |
| Mental Health Problem | 19 |
| Alcohol or other drug use | 7 |
| Psychological distress | 6 |
In current times, various technologies are being employed to treat mental health illnesses. These technologies, often referred to as eHealth or telemedicine, enhance traditional therapeutic practices and provide better healthcare for mental disorders. They offer improved effectiveness, accessibility, affordability, and robustness compared to traditional methods. Some of the technology-based approaches used in treating mental health illnesses include:
- Machine Learning and Predictive Models:
-
- Predicting Schizophrenia Machine learning approaches utilize datasets containing genetic, clinical, and brain magnetic resonance imaging (BMRI) information to predict Schizophrenia. Random forest, logistic regression, and deep learning algorithms have been employed with accuracy consistently above 72%.
- Predicting Depression and Anxiety: Machine learning models such as Support Vector Machine (SVM), K-nearest neighbor, and convolutional neural networks are used to recognize the degree of depression and anxiety. These models achieve prediction accuracies ranging from 70% to 96%.
- Predicting Bipolar Disorder: Pattern recognition and Gaussian process classification algorithms are used to identify bipolar disorder patients from healthy controls. Support Vector Machine (SVM) algorithms are effective in differentiating bipolar patients from unipolar patients. Functional magnetic resonance imaging (fMRI) helps explore brain activity differences. The accuracy of these models is typically above 70%.
- Predicting PTSD: Machine learning algorithms like random forest and ensemble classifiers like AdaBoost are utilized to predict the range of depression and PTSD among social media users. Techniques such as random forest, bagging classifier, support vector machine, and artificial neural network have achieved high accuracy. Gradient-boosted decision trees are also used on well-structured datasets to attain accurate predictions.
- Innovative Technological Approaches:
-
- Prescription Video Games: Video games designed specifically for therapeutic purposes are used to address mental health issues.
- AI and Smartphone-Assisted Therapy: Artificial intelligence (AI) and smartphone applications provide assistance and guidance for therapy, offering personalized recommendations and interventions.
- VR and AR for Mental Health: Virtual reality (VR) and augmented reality (AR) technologies are employed for exposure therapy, relaxation techniques, and immersive interventions.
- Wearables and Digital Biomarker Apps: Wearable devices and apps monitor physiological and behavioral data to provide insights into mental health conditions.
- Digital Pills: Sensor-embedded medications can track ingestion patterns and monitor medication adherence.
- Digital Symptom Tracking: Smartphone apps and digital platforms help individuals track and manage their symptoms, providing valuable data for treatment.
- Metaverse for Mental Health: The concept of a metaverse, an immersive virtual reality space, is explored for mental health interventions and support.
These technological advancements have revolutionized the field of mental health treatment, providing innovative approaches to diagnosis, prediction, therapy, and support. Researchers and medical centers are actively leveraging these technologies to improve the well-being of individuals with mental health issues.
System Architecture:
OSMI (Open Source Mental Illness) is an organization dedicated to raising awareness, providing education, and offering tools to support mental well-being in the IT and open source communities. They undertake various initiatives, such as distributing ebooks on mental wellness in the workplace, hosting mental health forums, and delivering speeches about mental health at developer conferences.
As part of their initiatives, OSMI conducts a survey on mental health in the IT industry. This survey collects data on respondents’ mental health, demographics, and employer attitudes towards mental health in the workplace. The survey was carried out in 2014, 2016, 2017, 2018, and 2019. For this project, the data from all five years has been consolidated into one comprehensive dataset. Consolidating the data from multiple years increases the likelihood of accurate predictions by providing a larger and more diverse set of data to learn from.
The survey questionnaire covers various aspects, including age, gender, location, region of work, and type of work (e.g., front-end development, design, and marketing). There are three key questions in the survey that are vital in identifying individuals with mental health conditions:
- “Have you had a mental health disorder sometime in the past?”
- “Do you currently have a mental health disorder?”
- “Have you been diagnosed by a medical expert with a mental health condition?”
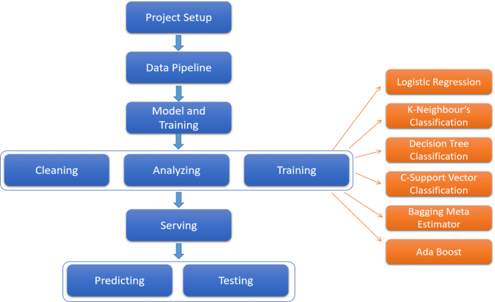
The project is divided into three sections: cleaning, analyzing, and training.
- Cleaning: Data cleaning involves reviewing the entire database and removing or updating any incomplete, inaccurate, incorrectly structured, duplicated, or unnecessary information. Data cleansing improves data quality, leading to enhanced productivity and reduced costs by eliminating outdated or erroneous information.
- Analyzing: Data analysis involves examining, transforming, and modeling the data to extract meaningful insights, inform conclusions, and support decision-making. It helps separate valuable information from noise and facilitates visualization to help interpret the data effectively. The project utilizes diagnostic analysis to identify the reasons behind certain events and understand the parameters that are essential for assessing someone’s mental health.
- Training: Training data plays a crucial role in machine learning by enabling machines to detect patterns and make accurate predictions when applied to real-life scenarios. In this phase, the insights gained from data analysis are used to train the models, allowing them to learn the patterns and characteristics of the data. The project employs both training and testing data, with a 60:40 split. The models learn from the training data and are then tested on the separate testing data.
The serving phase is divided into two sections: predicting and testing.
- Predicting: Prediction refers to the output of an algorithm after being trained on a previous dataset and applied to new data. The algorithm predicts the most probable values for an unknown variable in the new data. This is the stage where the application interacts with the user, and based on its training and model, it provides predictions or results. The models used in this project include Logistic Regression, KNN classification, Decision Tree Classification, C-Support Vector Classification, Bagging Meta Estimator, and AdaBoost.
- Testing: In this phase, the performance of the machine learning models is evaluated using metrics and charts over a validation dataset. Multiple models can be compared, and relative judgments can be made regarding their performance.
By following this data pipeline, OSMI aims to gain insights into mental health in the IT industry, identify patterns and factors related to mental health conditions, and develop models that can make predictions or provide valuable information for mental well-being support.
Implementation
It consists of three main procedures: data cleaning, data analysis and visualization, and supervised learning or modeling.
Data cleaning is the process of cleaning and combining datasets to prepare them for exploratory data analysis. Data cleaning is considered essential in data modeling and project implementation. The steps involved in data cleaning include importing necessary modules, applying warning filters, importing essential packages and libraries, importing datasets from multiple years, removing impurities from the dataset, handling null or impure values, cleaning the dataset based on age and gender, seeking treatment for mental health conditions, discussing prior experiences of mental health, analyzing anonymity, reaction rates, negative consequences, respondent locations, accessing mental health resources, history of diagnoses, insurances, openness to discussion, responsible employers, types of disorders and syndromes, and finally, typecasting and saving the cleaned dataset. The process also involves visualizing missing values and saving the cleaned dataset as a CSV file.
Data Analysis:
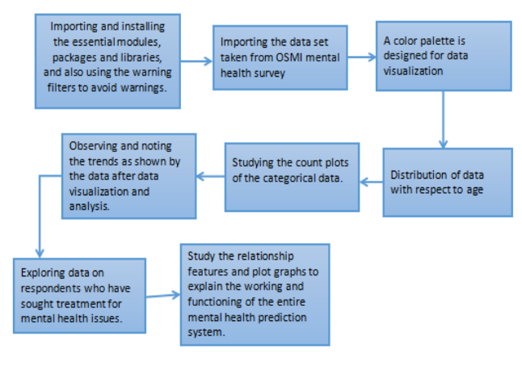
Using the cleaned OSMI dataset, we conducted exploratory data analysis (EDA) and visualizations. We imported necessary libraries such as Pandas, Seaborn, Pyplot, and _log for plotting logarithmic axes and suppressed warnings for concise output.
We created several figures to analyze the data with respect to age. Figure 7 is a distribution plot; Figure 8 is a count plot; and Figure 9 is a boxen plot. These visualizations revealed that a majority of the survey respondents were between the ages of 20 and 40.
Count plots were used to identify further insights from the survey data. Based on these plots, we observed the following:
- A significant number of respondents were from the USA or other developed countries, where mental health insurance coverage is common.
- Many respondents preferred to remain anonymous when discussing mental health issues.
- A considerable number of individuals reported having mental health disorders such as PTSD, anxiety, bipolar disorder, etc.
- Females showed a higher prevalence of family histories of mental health issues.
- Transgender individuals, “Others” in the gender category, and members of the LGBTQ+ community were more likely to experience mental health illnesses, particularly depression, anxiety, PTSD, etc.
We also analyzed the categorical data related to employability as a factor in observing and treating mental health issues. The following insights were gathered:
- Respondents believed that their workplace should make more efforts to support mental health issues.
- Some respondents were uncomfortable discussing mental health concerns with colleagues at their company.
- In many large companies, employees hesitate to address mental health issues due to fears of negative consequences.
- Certain companies lacked sufficient resources for educating people about mental health problems.
Furthermore, we explored the data on respondents who sought treatment for mental health issues. Key observations include:
- Respondents who had been diagnosed with a mental health disorder in the past and those with a family history of mental illness were more likely to seek treatment.
- Some respondents had attempted to seek medical help but were still uncomfortable discussing it openly.
To examine the relationships discussed through graphs, we created a heatmap of correlations. This visualization provided insights into the various connections between different variables.
Supervised Models:
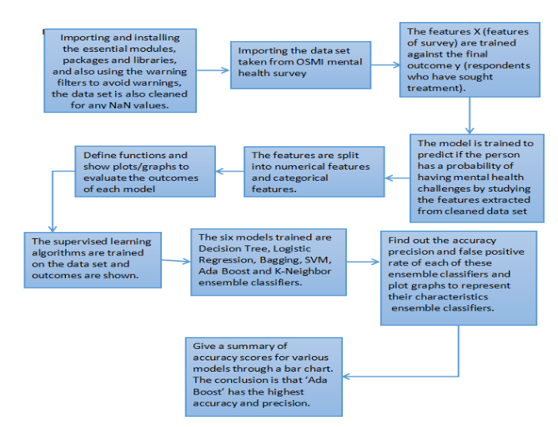
To perform supervised learning on the cleaned OSMI dataset, we import the necessary libraries, such as numpy and pandas, and read the cleaned dataset into a variable called ‘survey’. The target variable, ‘Sought Treatment’, is stored in the variable ‘y’.
We define a method called ‘bestFill’ to handle missing or null values by filling them with desired values based on their data types. This is done by passing the ‘survey’ variable as an argument. Numeric and categorical features are split into separate variables, ‘numerical_features’ and ‘categorical_features’, respectively.
Since data points with large differences can affect accuracy, we apply scaling to generalize the data points. Numeric features are scaled using StandardScaler, which standardizes each input variable separately. Categorical data is scaled using OneHotEncoder, which creates new columns for each category.
Next, we split the dataset into training and testing data in a 60:40 ratio.
We define a method called ‘evaluateModel’ to evaluate and compare the outcomes of different models. The method takes the model and predicted values as inputs. It calculates and prints the accuracy score, confusion matrix, precision score, and ROC AUC score. It also plots the confusion matrix, histogram of predicted probabilities, and ROC curve.
We train and test several supervised learning models on the dataset and display their outcomes:
- C-Support Vector Classifier: We use the SVC library to define the support vector machine classifier. The accuracy score is 80.33%.
- Logistic Regression Classifier: We use the LogisticRegression library to define the logistic regression classifier. The accuracy score is 80.86%.
- K-Neighbors Classifier: We use the KNeighborsClassifier library to define the k-neighbors classifier. The accuracy score is 78.19%.
- Decision Tree Classifier: We use the DecisionTreeClassifier library to define the decision tree classifier. The accuracy score is 72.75%.
- Bagging Classifier: We use the BaggingClassifier library to define the bagging classifier. The accuracy score is 79.62%.
- AdaBoost Classifier: We use the AdaBoostClassifier library to define the AdaBoost classifier. The accuracy score is 81.46%, which is the highest among all the models.
These models are evaluated based on their accuracy, precision, and ROC AUC score to compare their performance in predicting the sought Treatment’ variable.
Machine Learning Models and Ensemble Classifiers
- Initialize the weights of the training examples. Each example is assigned an equal weight.
- Train a weak classifier on the training set. A weak classifier is a simple classifier that performs slightly better than random guessing.
- Calculate the weighted error of the weak classifier. The weighted error is the sum of weights of misclassified examples.
- Calculate the weight of the weak classifier. The weight is determined by the classifier’s accuracy in classifying the examples.
- Update the weights of the training examples. Increase the weights of misclassified examples so they have a higher influence in the next iteration.
- Normalize the weights of the training examples to ensure they sum up to 1.
- Repeat steps 2–6 for a predefined number of iterations or until a stopping criterion is met.
- Combine the weak classifiers into a strong classifier by assigning weights to each weak classifier based on its accuracy.
- The final prediction is made by combining the predictions of the weak classifiers, weighted by their respective weights.
AdaBoost iteratively improves the performance by giving more weight to the examples that are difficult to classify correctly. It focuses on the examples that the weak classifiers struggle with and tries to find a combination of weak classifiers that works well together.
In summary, the selected machine learning models and ensemble classifiers in the project are:
- Logistic Regression
- K-Nearest Neighbors (KNN) Classification
- Decision Tree Classification
- C-Support Vector Classification (SVM)
- Bagging Meta-Estimation
- AdaBoost
These models have been trained on the dataset and evaluated based on accuracy, precision, ROC AUC score, and confusion matrix to assess their performance in predicting the target variable, “Sought Treatment.”
Result and Discussion
The project analysis clearly elaborates on the workings of this project. This leads to studying the results obtained and drawing relevant conclusions from them. Many researchers have proposed numerous methods for the hand gesture recognition system. But after reading them, we found that we could improve the same model with the help of deep learning and implement it in the real world using the latest technologies. We have taken six different Machine Learning models and ensemble classifiers for the project and calculated their accuracy and precision for comparison.
Accuracy: It gives us the percentage of correctly predicted observations.
Accuracy = (TP+TN)/(TP+FP+FN+TN)
Precision: It gives us the ratio of true positive observations to the total positive observations.
Precision = TP/(TP+FP)
Based on the analysis and results obtained from the six machine learning models and ensemble classifiers, the following conclusions can be drawn:
- Logistic Regression achieved an accuracy of 80.86% and a precision of 0.854. It performed well with a relatively low false-positive rate. The AUROC score of 0.88 indicates good performance.
- K-Nearest Neighbors (KNN) Classification achieved an accuracy of 78.19% and a precision of 0.815. It had a slightly higher false-positive rate compared to logistic regression. The AUROC score of 0.84 indicates good performance.
- C-Support Vector Classification achieved an accuracy of 80.33% and a precision of 0.848. It had a similar performance to logistic regression with a slightly lower false-positive rate. The AUROC score of 0.88 indicates good performance.
- Decision Tree Classification achieved an accuracy of 72.75% and a precision of 0.768. It had a higher false-positive rate compared to the previous models. The AUROC score of 0.72 indicates fair performance.
- Bagging Meta-Estimation achieved an accuracy of 79.62% and a precision of 0.834. It performed well overall, with a slightly higher false-positive rate compared to logistic regression and SVM. The AUROC score of 0.84 indicates good performance.
- AdaBoost achieved the highest accuracy of 81.46% and the highest precision of 0.857 among all the models. It had a relatively low false-positive rate and performed the best overall. The AUROC score of 0.88 indicates good performance.
Based on these results, it can be concluded that AdaBoost is the most effective model for predicting the target variable, “Sought Treatment,” in the given dataset. It outperformed the other models in terms of accuracy and precision. However, further analysis and evaluation of the models may be necessary to consider other factors such as computational complexity, scalability, and interpretability.
However, based on the information provided, it is clear that AdaBoost achieved the highest accuracy and precision among all the models evaluated. The accuracy scores of all the models are above 72%, which is considered a remarkable score given the limitations of the dataset.
AdaBoost is known for its versatility, parallelizability, high training speed, and ability to handle high-dimensional and unbalanced data. These factors likely contribute to its superior performance in this context.
The comparison of accuracies for all six models can be summarized as follows:
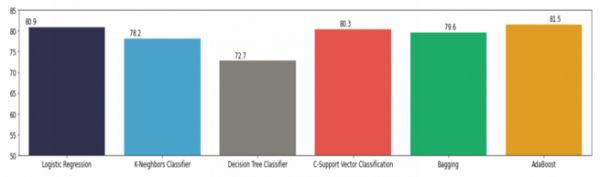
- Logistic Regression: Accuracy = 80.86%
- K-Nearest Neighbors (KNN): Accuracy = 78.19%
- C-Support Vector Classification: Accuracy = 80.33%
- Decision Tree: Accuracy: 72.75%
- Bagging Meta-Estimation: Accuracy = 79.62%
- AdaBoost: Accuracy = 81.46%
These results confirm that AdaBoost is the most effective model for the given task of mental health prediction based on the available dataset.
Impact on the Real World
The impact of this project on the real world is significant, particularly in the context of the tech industry and mental health. The project addresses the mental health challenges faced by working professionals in the tech industry, which can be attributed to factors such as competition, stress, and other personal circumstances. By using technology and machine learning models, this project aims to provide support and assistance to individuals in need.
The implementation of the prediction model can have several practical applications. It can be integrated into software, web applications, and mobile apps to provide personalized assistance and a platform for individuals to freely and securely discuss their mental health issues. This accessibility and ease of use can help people seek help and overcome their illnesses more effectively.
Furthermore, the project highlights the potential for further research and expansion. While the current dataset focuses on working professionals, future surveys and data collection efforts can include students, youngsters, and teenagers who also experience mental health issues such as anxiety and ADHD. By broadening the scope of the dataset, a more comprehensive understanding of mental health conditions can be achieved, leading to targeted interventions and support.
The project’s impact extends beyond the tech industry as well. By raising awareness about mental health and the role of technology in addressing it, the project contributes to improving mental health standards and overall well-being globally. It emphasizes the importance of creating empathetic and supportive work environments, promoting a better quality of life for individuals in the tech industry and beyond.
In summary, this project has the potential to make a positive impact by leveraging technology and machine learning to address mental health challenges in the tech industry. By providing support, raising awareness, and fostering empathy, it strives to improve the well-being of individuals and create a more inclusive and supportive work environment.
Conclusion :
In conclusion, mental health is a significant concern in the IT industry, where the pressure to perform well can negatively impact working professionals. Employers should prioritize the mental health of their employees by creating a supportive working environment and allowing flexible work schedules. Our predictive model, which utilizes various classifiers, can help companies better understand their employees’ mental health and provide the necessary support.
By using the prediction model, employees can have open conversations with their managers and colleagues about their mental health conditions. This communication can lead to necessary accommodations such as work-from-home options, flexible timing, and leaves when needed. However, there is still room for further research in the field of mental health using machine learning techniques.
Detailed research can be conducted by classifying mental health issues, such as depression, anxiety, bipolar disorder, and others, to provide more specific and tailored solutions. By expanding the reach of surveys like the OSMI survey to include more respondents and raising awareness about its benefits, we can gather more data and conduct more comprehensive research, potentially leading to higher accuracy and improved solutions.
In summary, our study compared different machine learning techniques to classify mental health problems using the OSMI survey dataset. The AdaBoost classifier achieved the highest accuracy of 81.5%, and all other classifiers also showed accuracy rates above 72%. By expanding the dataset and conducting further research, we can strive for even better accuracy and develop more effective solutions for mental health issues in the tech industry and beyond.




