What’s DataOps?
Within an organization, data managers and data consumers need the data to flow smoothly across the segments and verticals of the organization. This can be achieved through an associative data management practice that improves data flow communication, integration, and automation. Such practice allows the managers to predict the parameters of the delivery of the data, giving clarity on how the data would flow. This practice is called DataOps, and it is a technologically advanced platform that automates the data design, deploys data easily, and thus makes the data management feasible through proper governance. DataOps can be used in a dynamic environment as it is capable of using metadata so that data can be better used and carry value.
DataOps develops new insights for customers, maintains high quality data, facilitates different people, technologies, and environments to collaborate, and offers transparency in results that are clearly measured and monitored. DataSecOps, as the name suggests, is security within DataOps. Security for large amounts of data is crucial for organizations when it is accessible to large numbers of people within the organization as well as outside.
Why DataSecOps?
Data analysts require access to data. They need to know where the datasets reside in order to have quick access to them and clean, format, or standardize them so that they can be analyzed to gain insights. They need to perform this analysis within time-to-value so that the analysis can be useful in time. The time to gain access to the data is the time between the request to access it and obtaining it in the desired format. If the time gap between the request and receipt of data is long, it would hamper the progress of the project or make the analysis less useful.
DataSecOps is an excellent way of streamlining the process of allowing access to datasets. It automates some crucial aspects like data classification, access controls, data security, incident response, password management,and compliance within the data lakes, data lake houses, and data warehouses, empowering organizations to protect their valuable information effectively.
A graphic representation of a complete DataSecOps journey
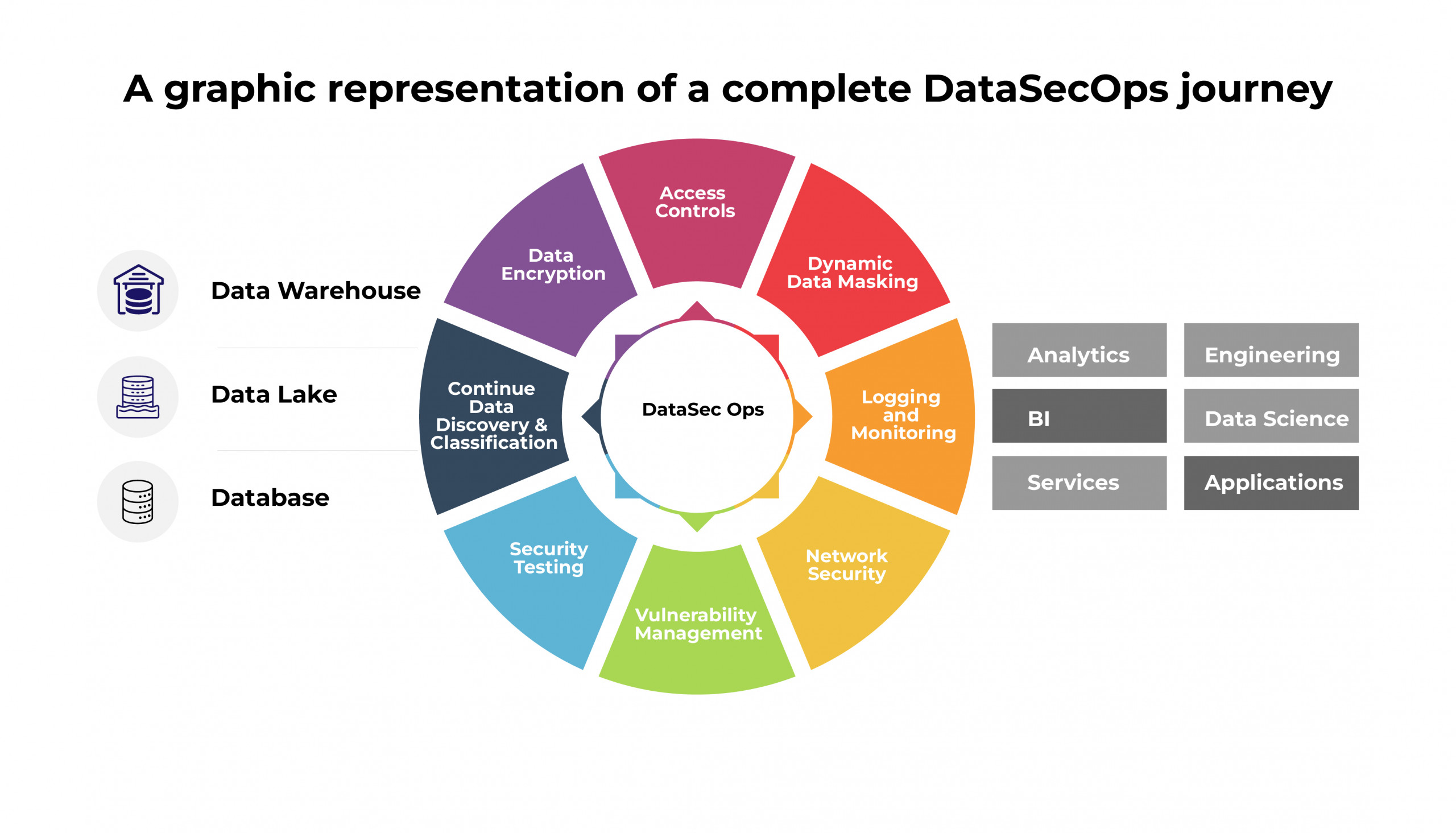
- Data discovery and classification: A Solid Foundation
Data keeps on changing, with more people touching it every day. Auditing or mapping your sensitive data once a year, even once a quarter or once a month, may not be sufficient.
The initial step in fortifying data security within GCP is meticulous data classification based on its sensitivity level. By identifying the types of data and their associated security requirements, organizations can better gauge the appropriate security controls. To effectively manage data security, start by classifying your data based on its sensitivity level. Categorize information as public, internal, confidential, or highly confidential. This classification will serve as a foundation for determining appropriate security controls and access privileges for each category. - Data Encryption: Protecting Data in Transit and at Rest
Ensuring data encryption both during transit and at rest is a fundamental component of data security. GCP offers diverse encryption options, including the Google Cloud Key Management Service (KMS) for efficient encryption key management, Cloud Storage encryption, and Cloud SQL transparent data encryption. By encrypting data, organizations can maintain its confidentiality and integrity, even in the event of a data breach, fortifying their overall security posture. - Access Controls: Guarding Data Perimeters
Implementing robust access controls is crucial for limiting data access to authorized individuals, employing the principle of least privilege. Leveraging Google Cloud’s Identity and Access Management (IAM) framework, organizations can proficiently manage roles and permissions for users and services. Adhering to the principle of granting minimal privileges necessary for users to carry out their tasks helps mitigate the risk of unauthorized access to sensitive data.
- Dynamic Data Masking (DDM)
DDM operates as a data security layer that resides between the database and the application layer. It employs a set of rules that determine how sensitive data should be obfuscated based on user roles and permissions. When a user initiates a query, DDM dynamically applies the defined masking rules, ensuring that the data presented to the user is masked or obfuscated. This approach provides a vital layer of protection, especially when dealing with sensitive data in non-production environments or granting limited access to third-party applications.
- Logging and Monitoring: A Watchful Eye
To detect and respond to any suspicious activities promptly, enabling robust audit logging and monitoring mechanisms is crucial. Employing tools such as Cloud Audit Logs, Stackdriver Logging, and Cloud Monitoring, organizations can gather and analyze comprehensive logs and metrics. By establishing alerts and notifications for security-related events, potential security incidents can be swiftly identified and appropriately addressed.
- Network Security: Safeguarding Data Transmission
Implementing effective network controls is vital for protecting data integrity. Leveraging Virtual Private Cloud (VPC) networks, firewall rules, and Cloud Load Balancing, organizations can effectively control traffic and secure communication between resources. This fortifies data against unauthorized access, ensuring its confidentiality and availability.
- Vulnerability Management: Continuous Protection
Regularly scanning the GCP infrastructure for vulnerabilities and promptly applying security patches and updates is crucial. GCP offers services such as the Cloud Security Scanner and Container Registry vulnerability scanning to assist in identifying and addressing security vulnerabilities. By proactively addressing known vulnerabilities, organizations can prevent potential security incidents, bolstering their defense against emerging threats.
- Security Testing: Unveiling Weaknesses
Conducting regular security testing, encompassing penetration testing and vulnerability assessments, is vital to identifying weaknesses and validating the effectiveness of security controls. Through diligent testing, potential security issues can be identified and rectified before malicious actors can exploit them, bolstering the overall security posture.
What is Data Observability?
Data observability is a process and set of practices that aim to help data teams understand the overall health of the data in their organization’s IT systems. Through the use of data observability techniques, data management and analytics professionals can monitor the quality, reliability, and delivery of data and identify issues that need to be addressed. Data observability is designed to help ensure healthy data pipelines, high data reliability, and timely data delivery, and to eliminate any data downtime, when errors, missing values, or other issues make data sets unusable. Each of the processes mentioned below ensures top class data quality and reliability.
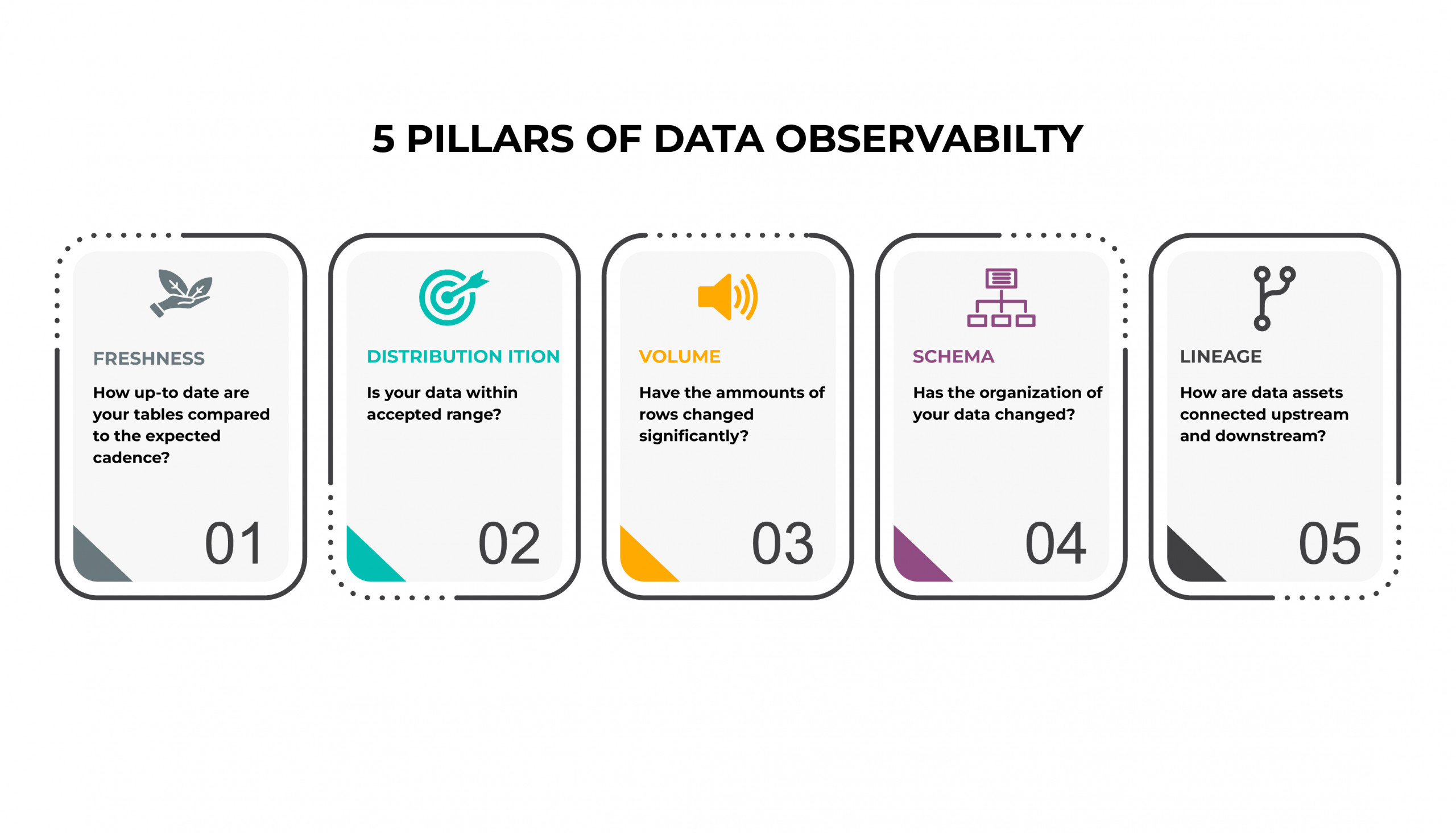
Data Freshness
You must measure, track, and assess a relevant data quality metric. In the case of data freshness, you can measure the difference between the latest timestamps and the present moment, the difference between a destination and a source system, verification against an expected rate of change, or corroboration against other pieces of data. One way to ensure data freshness is through anomaly detection, sometimes called outlier analysis, which helps you identify unexpected values or events in a data set.
Data Distribution
Data distribution, or data quality, is one of the most important aspects of observability. You need to ensure that the data flowing through is within the expected range. Data quality is considered a function of six different dimensions: Consistency, Completeness, Uniqueness, Timeliness, validity, and Accuracy. Hence, it’s very important to observe, manage, and maintain data quality.
Volume
It’s very important to detect any anomalies in the volume of data. You can monitor the use of storage at the volume extent level using the monitoring function. Monitoring statistics can be gathered and analyzed every 24 hours, and in case of discrepancies the results of this data can be summarized in a report and alerted to stakeholders. This can help define preventive measures and the root cause of incidents, and a pattern can be set for future resolutions.
Schema
Schema changes are definitely the riskiest part of any data driven project and become scarier as the data grows. A close eye needs to be kept to avoid unexpected issues. That’s why it is so important to automate schema change monitoring—to save teams loads of time and energy. In a multi-user environment, to keep the risks to a minimum, it is vitally important to regularly monitor changes made to the schema.
Lineage
Data lineage uncovers the life cycle of data—it aims to show the complete data flow, from start to finish. Data lineage is the process of understanding, recording, and visualizing data as it flows from data sources to consumption. This includes all transformations the data underwent along the way—how the data was transformed, what changed, and why. There can be many ways to achieve this, but the most advanced is lineage parsing. This technique reverse engineers data transformation logic to perform comprehensive, end-to-end tracing. This might include extract-transform-load (ETL) logic, SQL-based solutions, Java solutions, legacy data formats, XML based solutions, and so on.
What is its role in DataOps processes?
The goal of DataOps is to ensure that data is complete and accurate and can be accessed by the users who need it when they need it. This, in turn, can help ensure that an organization gets the maximum business value from its data. DataOps involves continuous integration and continuous delivery (CI/CD) and testing, orchestration, and monitoring of data assets and pipelines.
That list of tasks can now also include data observability. As part of DataOps processes, data engineers and other data professionals can use data observability techniques and tools to do the following:
- Monitor data sets, whether they’re at rest or in motion;
- Confirm that data formats, types and value ranges are as expected;
- Check for any anomalies, such as schema changes or sudden changes to data values, that could indicate a problem requiring remediation; and
- Track and optimize the performance of data pipelines.
The Power of Secure, Accessible Data
As we see, there is a rapid growth in data across organizations, and it will only grow manifold with time. No longer do we need to trade a risky open-to-all approach for a slow, manual need-to-know approach. It’s the need of the hour to have a robust DataSecOps platform that offers timely and secure need-to-know data access by ‘invisibly’ and automatically embedding access controls, security, observability, and governance right into data operations.
With this platform, companies will make more informed decisions, enhance compliance, reduce risk, and keep data highly accessible. And less time spent on ad-hoc access and security controls means companies can focus on what’s most important – connecting with customers, building better business models, and improving operations.




